LSM Store and Updates
This is the first part of a small series of blog posts about the upcoming StoreLSM and its design. My take on append-only log files, their compaction, snapshots and rollback.
All articles from ‘LSM Store’ series are under LSM tag.
During the past few months I have been working for IOHK on a new storage engine codenamed IODB. It is based on Log-Structured-Merge Tree and inspired by RocksDB from Facebook. IODB will be mostly used by block-chain applications. I really like LSM Trees and multi-threaded compaction in RocksDB. MapDB will eventually get a new StoreLSM engine, it will replace the old StoreAppend, and will be based on IODB design.
List of terms
First small list of terms used in this blog post (and this series).
Update is single atomic modification made on store. It inserts or deletes multiple keys. Synonym is Commit. Each Update creates Snapshot identified by version such as V0 or V1.
The linked-list is sequence of Updates linked together. Synonym could be append-only Log.
Log as Linked List of Updates
In Log-Structured store the current state (set of all persisted keys and values) is not stored on disk. Instead it contains a list of all Updates (CRUD operations). We can retrieve all entries for given version,
by replaying all Updates from the start (when store was empty) to the most recent update.
In my interpretation, the Updates are organized in a linked-list. The head of the linked-list is the most recent update. The tail of the linked-list is empty store, just after creation.
Links go only in a single direction (from newer to older Update), so all traversals have to go from head to tail (from the most recent Update to the oldest Update), Traversal in the opposite direction (from tail to head) is not possible. Special lazy-N-way merge is used to retrieve all persisted keys for given version
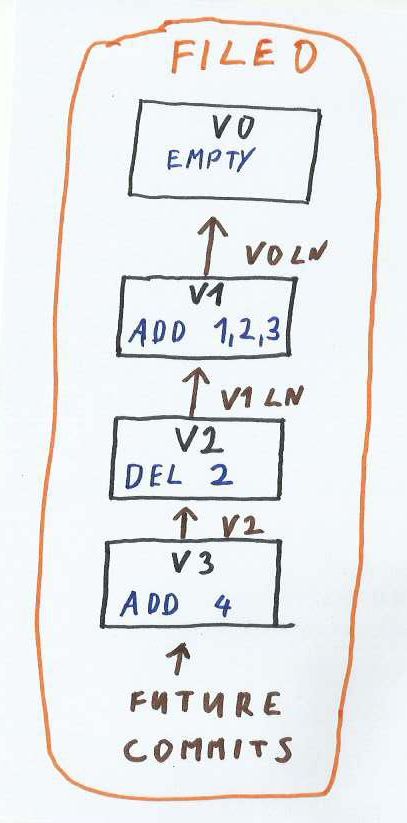
Sequence of updates as linked-list
In the figure above an empty store is created at version V0. The next Update inserts keys 1,2,3 and creates the new version V1. There is a link from V1 to V0.
The next update V2 deletes key 2 and creates a link to V1. The next V3 inserts key 4 and adds a link to V2.
The most recent version of the store is V2, with keys 1, 3 and 4. Key 2 has been deleted.
Find key
Key Search needs to find most recent version of key, in other words: it needs to find most recent Update when key was inserted, modified or deleted.
To find a key, we traverse a linked-list from the head (most recent update) to the tail (initial empty update). A linked-list traversal finishes when the most recent version of a key is found.
Deleted keys are indicated by ‘tombstones’; that is a special marker done as part of the key update. If a tombstone is found in the linked-list, it means that a key was deleted, and the search returns ‘not found’.
If a key does not exist (was never inserted or deleted), the entire linked-list is traversed and we reach tail (initial empty update). In this case the search also returns ‘not found’.
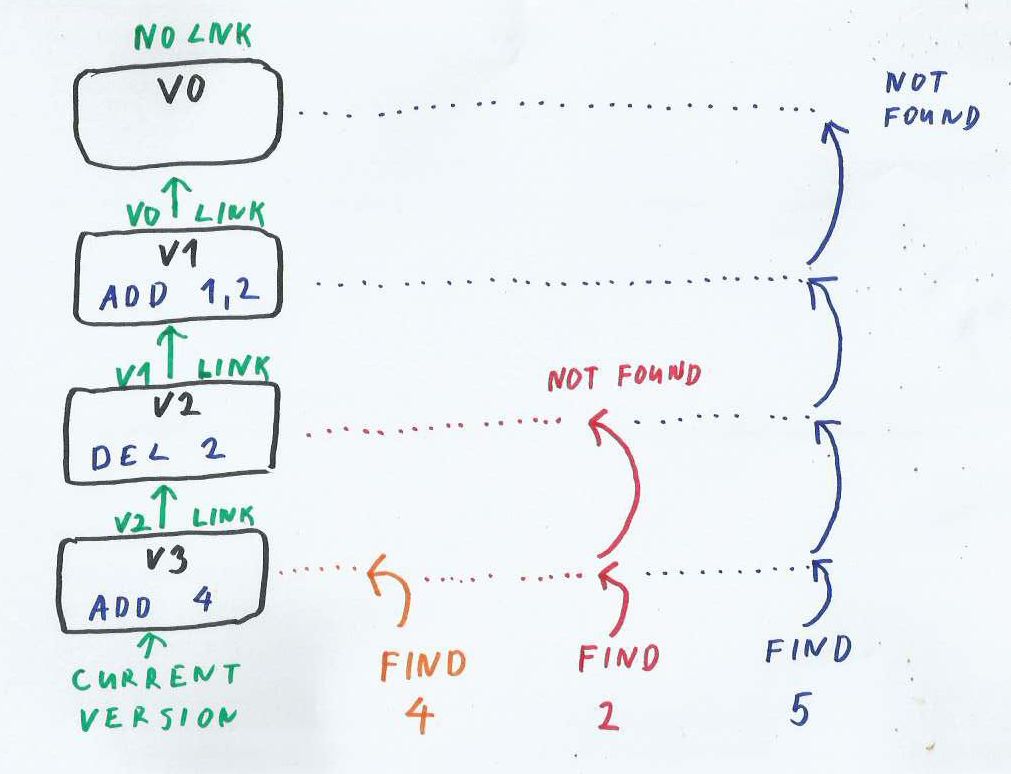
Search for the key in a sequence of Updates
The figure above shows a simple store with three updates:
- V1 adds 1,2;
- V2 deletes 2, vv
- V3 adds 4.
In the most recent version the store contains keys 1 and 4
On the right side is the sequence of steps used to find keys 4 (orange), 2 (red) and 5 (blue).
Key 4 (orange) was inserted in the most recent update (head of linked-list). So the traversal finishes at the first version.
Key 2 (red) was deleted and no longer exists in store. The search starts at V3, and follows the link to the previous update of V2. An update in V2 deleted this key, and contains its tombstone marker. So the most recent state of key 2 is ‘deleted’ and the search returns ‘not found’
Key 5 (blue) was never in log; it was never inserted or deleted. So the traversal goes from V3 -> V2 -> V1 and finally reaches the tail V0. There are no more links to follow, so the search returns ‘not found’.
Compaction and merge
As the number of updates grows and the linked-list gets longer, Find Key operation will become slow Also obsolete versions of keys are causing space overhead.
Both problems are solved by merging older updates into a single update. The merge is typically performed by a compaction process, which runs on the background in a separate thread.
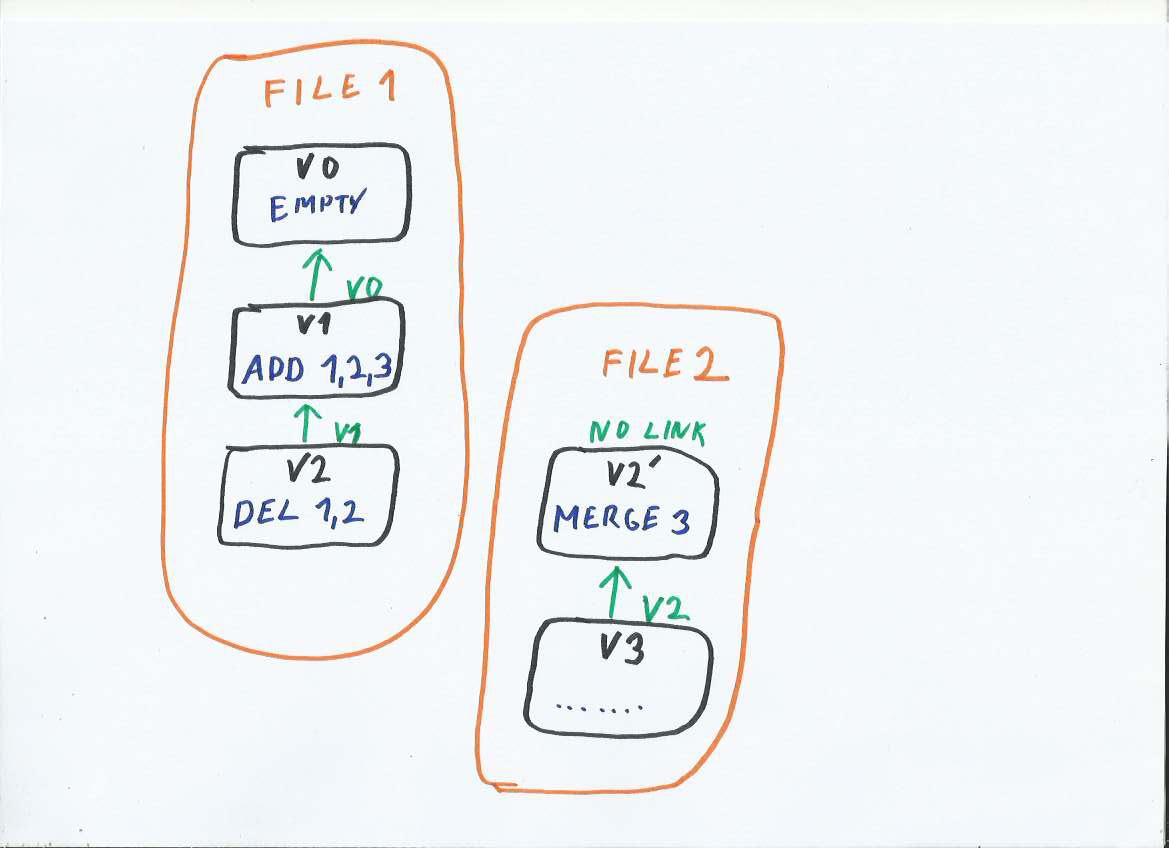
Merge three updates into a new file
The figure above shows a store with two updates:
- V1 inserts keys 1,2,3 and
- V2 deletes keys 1,2.
The most recent version of the store contains a single key 3.
There is wasted space occupied by inserted keys 1,2 and their tombstone markers. To reclaim this space we perform compaction.
Compaction replays all updates in the linked-list and retrieves a set of all entries for the most recent version (V2). For simplicity imagine it starts from V0 with an empty TreeSet<Key> and inserts or deletes keys, as it traverses the linked-list from tail to head (from the oldest to the most recent update).
The most recent store state (at V2 TreeSet will contain key 3) is written into a new Update with version V2’. This Update is the first entry in the new file. Basically we created new file, where the first Update is not empty, but it inserts all existing keys from the older file.
V2’ does not have a link to V1. It does not need it, because it contains all keys for given version and a linked-list traversal is not necessary after reaching V2’.
At this point we have two files: Older File 1 and newer File 2. It is safe to delete old File 1, as all data are contained in the newer file We also have two version with the same Version Identifier (V2 and V2’), this collision is resolved once the old file is deleted.
Merge algorithm
The analogy with compaction and TreeSet section is broken. A linked-list cannot really be traversed from tail to head, as all links go only in opposite directions. Also TreeSet is inefficient and all keys would not fit into memory.
Instead, compaction uses more effective lazy-N-way merge. I will describe it in more detail in a future blog post. In short:
Inside each Update Entry (such as V1, V2…), keys are stored in sorted order.
Compaction reads content of all Updates in parallel, and produces the result by comparing keys from all updates.
The time complexity is
O(N*log(U)), whereNis the total number of keys in all Updates andUis the number of Updates (versions) in merge.Compaction is streaming data; it never loads all keys into memory. But it needs to store
Ukeys in memory for comparison.If
Uis too large, the compaction process can be performed in stages.No random IO, as all reads are sequential and all writes are append-only.
Rollback
Most databases can rollback uncommitted changes. While inserting data into the database, you may decide to rollback or commit dirty (not yet saved) data.
LSM Store supports this scenario in more powerful way. Each update (commit) creates its own snapshot. It is possible to rollback several existing commits, and revert the store to an older version. This older version can then me modified independently in a separate branch. Original (rolled-back) data are not really lost, but are preserved in separate snapshot. Version Control System, such as Git, works in a similar way.
When rollback happens, the linked-list becomes a linked-tree with multiple heads. Each head represents one branch of updates.
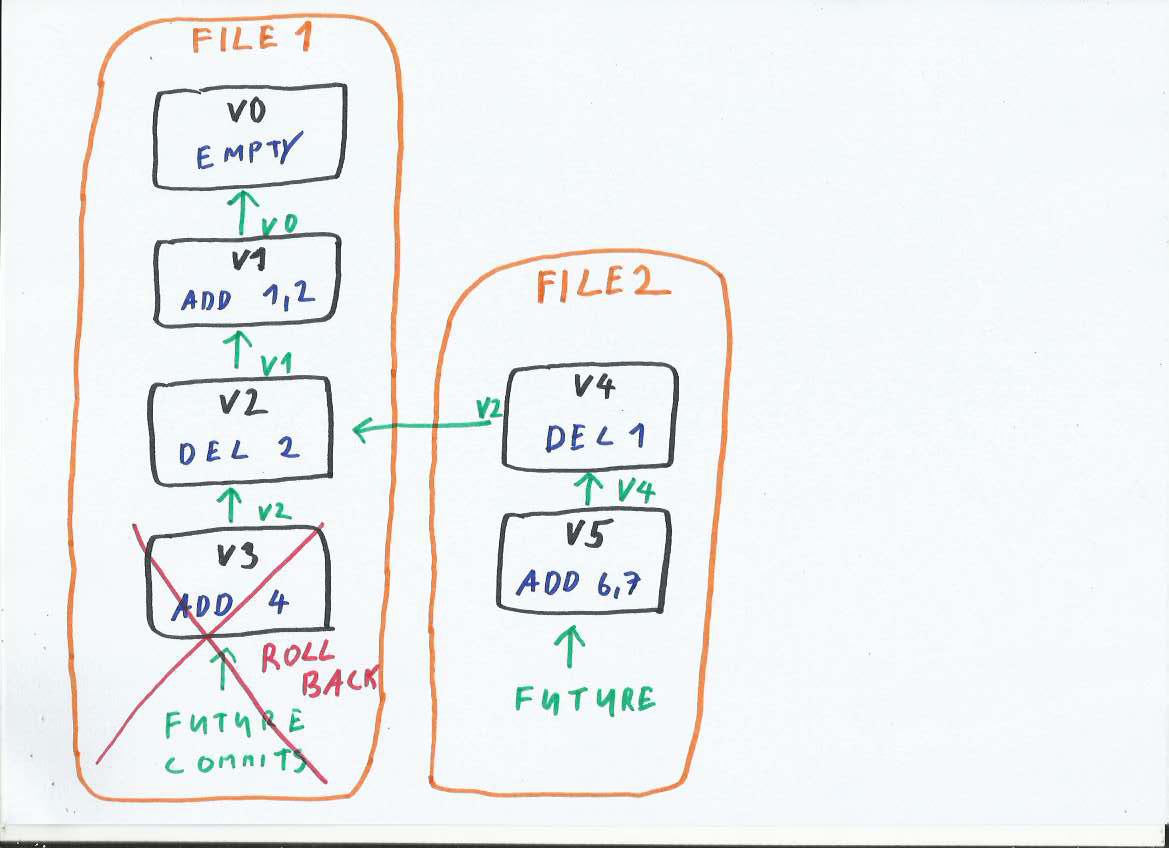
Rollback V3
The figure above shows such use case. We have a store with updates V1, V2 and V3. The last update V3 is rolled-back. And the linked-list will create a new branch from V2.
All updates are stored in File 1. This file is append-only, V3 was already written into the file, so we can not truncate the file and discard data from V3.
So the data from V3 will be preserved, but bypassed. We start the ‘new branch’ V4 with a direct link to V2. The skip-list with head V4 does not contain changes from V3.
There are multiple options where to place V4:
It could continue in File 1 after V3.
It could perform a merge operation and start a new File 2, in this case the old File 1 would become obsolete and could be deleted.
In the figure above we continue the linked-list in new File 2 without performing merge. This effectively creates two branches (with heads V3 and V4); both of those can be modified and accept the new updates (commits):
We can modify the old V3 branch. In that case, the updates will go to File 1 and their links will point to V3.
We can also modify the new V4 branch. In this case, the changes will got to File 2 and their links will point to V4.
So this LSM Store supports a classic rollback, but it can also create branches from older snapshots. It is similar to Git (or other VCSs). Data can exist in multiple versions and branches. All versions are preserved and can be queried or modified.
Snapshots and branches are necessary for blockchain applications. In this use case multiple branches exist concurrently, until the consensus algorithm decides which branch wins and becomes the new main branch.
The upcoming StoreLSM will support branching as an optional feature.
Update entries and files
In this post I have been quite vague about how Updates (data chunk created by each update/commit) are organized into files. It depends on the usage pattern. I will go into more details in a future post, but for now I expect three usages:
Put all the updates into a single append-only file and never perform merge
Put each update into a separate file. This is good if there are many branches and rollbacks (for example IODB with blockchain). The older versions can be easily discarded by merging and removing their files.
Most scenarios will not need to rollback too many versions. So I expect there will be a single main file, with merged content at beginning. The basic algorithm goes this way:
Multiple updates are grouped into a single ‘main file’
The first update in the ‘main file’ inserts merged content from an older file.
New updates will be appended to the end of the ‘main file’.
Once the ‘main file’ has too many updates, compaction starts merging its content into a ‘new file’ in the background process.
After merging finishes, the ‘new file’ becomes the ‘main file’ and the old file is deleted.
New updates will be appended at the end of the ‘main file’ … and the cycle continues